Despite significant successes achieved in knowledge discovery, traditional machine learning methods may fail to obtain satisfactory performances when dealing with complex data, such as imbalanced, high-dimensional, noisy data, etc. The reason behind is that it is difficult for these methods to capture multiple characteristics and underlying structure of data. In this context, it becomes an important topic in the data mining field that how to effectively construct an efficient knowledge discovery and mining model. Ensemble learning, as one research hot spot, aims to integrate data fusion, data modeling, and data mining into a unified framework. Specifically, ensemble learning firstly extracts a set of features with a variety of transformations. Based on these learned features, multiple learning algorithms are utilized to produce weak predictive results. Finally, ensemble learning fuses the informative knowledge from the above results obtained to achieve knowledge discovery and better predictive performance via voting schemes in an adaptive way. In this paper, we review the research progress of the mainstream approaches of ensemble learning and classify them based on different characteristics. In addition, we present challenges and possible research directions for each mainstream approach of ensemble learning, and we also give an extra introduction for the combination of ensemble learning with other machine learning hot spots such as deep learning, reinforcement learning, etc.
There has been a growing interest in the side-channel analysis (SCA) field based on deep learning (DL) technology. Various DL network or model has been developed to improve the efficiency of SCA. However, few studies have investigated the impact of the different models on attack results and the exact relationship between power consumption traces and intermediate values. Based on the convolutional neural network and the autoencoder, this paper proposes a Template Analysis Pre-trained DL Classification model named TAPDC which contains three sub-networks. The TAPDC model detects the periodicity of power trace, relating power to the intermediate values and mining the deeper features by the multi-layer convolutional net. We implement the TAPDC model and compare it with two classical models in a fair experiment. The evaluative results show that the TAPDC model with autoencoder and deep convolution feature extraction structure in SCA can more effectively extract information from power consumption trace. Also, Using the classifier layer, this model links power information to the probability of intermediate value. It completes the conversion from power trace to intermediate values and greatly improves the efficiency of the power attack.

Having a formal model of neural networks can greatly help in understanding and verifying their properties, behavior, and response to external factors such as disease and medicine. In this paper, we adopt a formal model to represent neurons, some neuronal graphs, and their composition. Some specific neuronal graphs are known for having biologically relevant structures and behaviors and we call them archetypes. These archetypes are supposed to be the basis of typical instances of neuronal information processing. In this paper we study six fundamental archetypes (simple series, series with multiple outputs, parallel composition, negative loop, inhibition of a behavior, and contralateral inhibition), and we consider two ways to couple two archetypes: (i) connecting the output(s) of the first archetype to the input(s) of the second archetype and (ii) nesting the first archetype within the second one. We report and compare two key approaches to the formal modeling and verification of the proposed neuronal archetypes and some selected couplings. The first approach exploits the synchronous programming language Lustre to encode archetypes and their couplings, and to express properties concerning their dynamic behavior. These properties are verified thanks to the use of model checkers. The second approach relies on a theorem prover, the Coq Proof Assistant, to prove dynamic properties of neurons and archetypes.

Blind source extraction (BSE) is particularly attractive to solve blind signal mixture problems where only a few source signals are desired. Many existing BSE methods do not take into account the existence of noise and can only work well in noise-free environments. In practice, the desired signal is often contaminated by additional noise. Therefore, we try to tackle the problem of noisy component extraction. The reference signal carries enough prior information to distinguish the desired signal from signal mixtures. According to the useful properties of Gaussian moments, we incorporate the reference signal into a negentropy objective function so as to guide the extraction process and develop an improved BSE method. Extensive computer simulations demonstrate its validity in the process of revealing the underlying desired signal.
Finger vein biometrics have been extensively studied for the capability to detect aliveness, and the high security as intrinsic traits. However, vein pattern distortion caused by finger rotation degrades the performance of CNN in 2D finger vein recognition, especially in a contactless mode. To address the finger posture variation problem, we propose a 3D finger vein verification system extracting axial rotation invariant feature. An efficient 3D finger vein reconstruction optimization model is proposed and several accelerating strategies are adopted to achieve real-time 3D reconstruction on an embedded platform. The main contribution in this paper is that we are the first to propose a novel 3D point-cloud-based end-to-end neural network to extract deep axial rotation invariant feature, namely 3DFVSNet. In the network, the rotation problem is transformed to a permutation problem with the help of specially designed rotation groups. Finally, to validate the performance of the proposed network more rigorously and enrich the database resources for the finger vein recognition community, we built the largest publicly available 3D finger vein dataset with different degrees of finger rotation, namely the Large-scale Finger Multi-Biometric Database-3D Pose Varied Finger Vein (SCUT LFMB-3DPVFV) Dataset. Experimental results on 3D finger vein datasets show that our 3DFVSNet holds strong robustness against axial rotation compared to other approaches.

Nowadays, smart buildings rely on Internet of things (IoT) technology derived from the cloud and fog computing paradigms to coordinate and collaborate between connected objects. Fog is characterized by low latency with a wider spread and geographically distributed nodes to support mobility, real-time interaction, and location-based services. To provide optimum quality of user life in modern buildings, we rely on a holistic Framework, designed in a way that decreases latency and improves energy saving and services efficiency with different capabilities. Discrete EVent system Specification (DEVS) is a formalism used to describe simulation models in a modular way. In this work, the sub-models of connected objects in the building are accurately and independently designed, and after installing them together, we easily get an integrated model which is subject to the fog computing Framework. Simulation results show that this new approach significantly, improves energy efficiency of buildings and reduces latency. Additionally, with DEVS, we can easily add or remove sub-models to or from the overall model, allowing us to continually improve our designs.

Microblogging provides a new platform for communicating and sharing information amongWeb users. Users can express opinions and record daily life using microblogs. Microblogs that are posted by users indicate their interests to some extent. We aim to mine user interests via keyword extraction from microblogs. Traditional keyword extraction methods are usually designed for formal documents such as news articles or scientific papers. Messages posted by microblogging users, however, are usually noisy and full of new words, which is a challenge for keyword extraction. In this paper, we combine a translation-based method with a frequency-based method for keyword extraction. In our experiments, we extract keywords for microblog users from the largest microblogging website in China, Sina Weibo. The results show that our method can identify users’ interests accurately and efficiently.
Massive scale of transactions with critical requirements become popular for emerging businesses, especially in E-commerce. One of the most representative applications is the promotional event running on Alibaba’s platform on some special dates, widely expected by global customers. Although we have achieved significant progress in improving the scalability of transactional database systems (OLTP), the presence of contention operations in workloads is still one of the fundamental obstacles to performance improving. The reason is that the overhead of managing conflict transactions with concurrency control mechanisms is proportional to the amount of contentions. As a consequence, generating contented workloads is urgent to evaluate performance of modern OLTP database systems. Though we have kinds of standard benchmarks which provide some ways in simulating contentions, e.g., skew distribution control of transactions, they can not control the generation of contention quantitatively; even worse, the simulation effectiveness of these methods is affected by the scale of data. So in this paper we design a scalable quantitative contention generation method with fine contention granularity control. We conduct a comprehensive set of experiments on popular opensourced DBMSs compared with the latest contention simulation method to demonstrate the effectiveness of our generation work.

In the past decade, recommender systems have been widely used to provide users with personalized products and services. However, most traditional recommender systems are still facing a challenge in dealing with the huge volume, complexity, and dynamics of information. To tackle this challenge, many studies have been conducted to improve recommender system by integrating deep learning techniques. As an unsupervised deep learning method, autoencoder has been widely used for its excellent performance in data dimensionality reduction, feature extraction, and data reconstruction. Meanwhile, recent researches have shown the high efficiency of autoencoder in information retrieval and recommendation tasks. Applying autoencoder on recommender systems would improve the quality of recommendations due to its better understanding of users’ demands and characteristics of items. This paper reviews the recent researches on autoencoder-based recommender systems. The differences between autoencoder-based recommender systems and traditional recommender systems are presented in this paper. At last, some potential research directions of autoencoder-based recommender systems are discussed.
The cryo-electron microscopy (cryo-EM) is one of the most powerful technologies available today for structural biology. The RELION (Regularized Likelihood Optimization) implements a Bayesian algorithm for cryo-EM structure determination, which is one of the most widely used software in this field. Many researchers have devoted effort to improve the performance of RELION to satisfy the analysis for the ever-increasing volume of datasets. In this paper, we focus on performance analysis of the most time-consuming computation steps in RELION and identify their performance bottlenecks for specific optimizations. We propose several performance optimization strategies to improve the overall performance of RELION, including optimization of expectation step, parallelization of maximization step, accelerating the computation of symmetries, and memory affinity optimization. The experiment results show that our proposed optimizations achieve significant speedups of RELION across representative datasets. In addition, we perform roofline model analysis to understand the effectiveness of our optimizations.

Autonomous agents have long been a research focus in academic and industry communities. Previous research often focuses on training agents with limited knowledge within isolated environments, which diverges significantly from human learning processes, and makes the agents hard to achieve human-like decisions. Recently, through the acquisition of vast amounts of Web knowledge, large language models (LLMs) have shown potential in human-level intelligence, leading to a surge in research on LLM-based autonomous agents. In this paper, we present a comprehensive survey of these studies, delivering a systematic review of LLM-based autonomous agents from a holistic perspective. We first discuss the construction of LLM-based autonomous agents, proposing a unified framework that encompasses much of previous work. Then, we present a overview of the diverse applications of LLM-based autonomous agents in social science, natural science, and engineering. Finally, we delve into the evaluation strategies commonly used for LLM-based autonomous agents. Based on the previous studies, we also present several challenges and future directions in this field.

In this paper, we present an efficient algorithm that generates lip-synchronized facial animation from a given vocal audio clip. By combining spectral-dimensional bidirectional long short-term memory and temporal attention mechanism, we design a light-weight speech encoder that learns useful and robust vocal features from the input audio without resorting to pre-trained speech recognition modules or large training data. To learn subject-independent facial motion, we use deformation gradients as the internal representation, which allows nuanced local motions to be better synthesized than using vertex offsets. Compared with state-of-the-art automatic-speech-recognition-based methods, our model is much smaller but achieves similar robustness and quality most of the time, and noticeably better results in certain challenging cases.

Blockchain has recently emerged as a research trend, with potential applications in a broad range of industries and context. One particular successful Blockchain technology is smart contract, which is widely used in commercial settings (e.g., high value financial transactions). This, however, has security implications due to the potential to financially benefit froma security incident (e.g., identification and exploitation of a vulnerability in the smart contract or its implementation). Among, Ethereum is the most active and arresting. Hence, in this paper, we systematically review existing research efforts on Ethereum smart contract security, published between 2015 and 2019. Specifically, we focus on how smart contracts can be maliciously exploited and targeted, such as security issues of contract program model, vulnerabilities in the program and safety consideration introduced by program execution environment. We also identify potential research opportunities and future research agenda.
GPUs are widely used in modern high-performance computing systems. To reduce the burden of GPU programmers, operating system and GPU hardware provide great supports for shared virtual memory, which enables GPU and CPU to share the same virtual address space. Unfortunately, the current SIMT execution model of GPU brings great challenges for the virtual-physical address translation on the GPU side, mainly due to the huge number of virtual addresses which are generated simultaneously and the bad locality of these virtual addresses. Thus, the excessive TLB accesses increase the miss ratio of TLB. As an attractive solution, Page Walk Cache (PWC) has received wide attention for its capability of reducing the memory accesses caused by TLB misses.
However, the current PWC mechanism suffers from heavy redundancies, which significantly limits its efficiency. In this paper, we first investigate the facts leading to this issue by evaluating the performance of PWC with typical GPU benchmarks. We find that the repeated L4 and L3 indices of virtual addresses increase the redundancies in PWC, and the low locality of L2 indices causes the low hit ratio in PWC. Based on these observations, we propose a new PWC structure, namely Compressed Page Walk Cache (CPWC), to resolve the redundancy burden in current PWC. Our CPWC can be organized in either direct-mapped mode or set-associated mode. Experimental results show that CPWC increases by 3 times over TPC in the number of page table entries, increases by 38.3% over PWC in L2 index hit ratio and reduces by 26.9% in the memory accesses of page tables. The average memory accesses caused by each TLB miss is reduced to 1.13. Overall, the average IPC can improve by 25.3%.

The problem of subgraph matching is one fundamental issue in graph search, which is NP-Complete problem. Recently, subgraph matching has become a popular research topic in the field of knowledge graph analysis, which has a wide range of applications including question answering and semantic search. In this paper, we study the problem of subgraph matching on knowledge graph. Specifically, given a query graph

The maintainability of source code is a key quality characteristic for software quality. Many approaches have been proposed to quantitatively measure code maintainability. Such approaches rely heavily on code metrics, e.g., the number of Lines of Code and McCabe’s Cyclomatic Complexity. The employed code metrics are essentially statistics regarding code elements, e.g., the numbers of tokens, lines, references, and branch statements. However, natural language in source code, especially identifiers, is rarely exploited by such approaches. As a result, replacing meaningful identifiers with nonsense tokens would not significantly influence their outputs, although the replacement should have significantly reduced code maintainability. To this end, in this paper, we propose a novel approach (called DeepM) to measure code maintainability by exploiting the lexical semantics of text in source code. DeepM leverages deep learning techniques (e.g., LSTM and attention mechanism) to exploit these lexical semantics in measuring code maintainability. Another key rationale of DeepM is that measuring code maintainability is complex and often far beyond the capabilities of statistics or simple heuristics. Consequently, DeepM leverages deep learning techniques to automatically select useful features from complex and lengthy inputs and to construct a complex mapping (rather than simple heuristics) from the input to the output (code maintainability index). DeepM is evaluated on a manually-assessed dataset. The evaluation results suggest that DeepM is accurate, and it generates the same rankings of code maintainability as those of experienced programmers on 87.5% of manually ranked pairs of Java classes.

Recent studies have shown remarkable success in face image generation task. However, existing approaches have limited diversity, quality and controllability in generating results. To address these issues, we propose a novel end-to-end learning framework to generate diverse, realistic and controllable face images guided by face masks. The face mask provides a good geometric constraint for a face by specifying the size and location of different components of the face, such as eyes, nose and mouse. The framework consists of four components: style encoder, style decoder, generator and discriminator. The style encoder generates a style code which represents the style of the result face; the generator translate the input face mask into a real face based on the style code; the style decoder learns to reconstruct the style code from the generated face image; and the discriminator classifies an input face image as real or fake. With the style code, the proposed model can generate different face images matching the input face mask, and by manipulating the face mask, we can finely control the generated face image. We empirically demonstrate the effectiveness of our approach on mask guided face image synthesis task.

In this paper, we propose a new lightweight block cipher called SCENERY. The main purpose of SCENERY design applies to hardware and software platforms. SCENERY is a 64-bit block cipher supporting 80-bit keys, and its data processing consists of 28 rounds. The round function of SCENERY consists of 8 4 × 4 S-boxes in parallel and a 32 × 32 binary matrix, and we can implement SCENERY with some basic logic instructions. The hardware implementation of SCENERY only requires 1438 GE based on 0.18 um CMOS technology, and the software implementation of encrypting or decrypting a block takes approximately 1516 clock cycles on 8-bit microcontrollers and 364 clock cycles on 64-bit processors. Compared with other encryption algorithms, the performance of SCENERY is well balanced for both hardware and software. By the security analyses, SCENERY can achieve enough security margin against known attacks, such as differential cryptanalysis, linear cryptanalysis, impossible differential cryptanalysis and related-key attacks.

Most current crowdsourced logistics aim to minimize systems cost and maximize delivery capacity, but the efforts of crowdsourcers such as drivers are almost ignored. In the delivery process, drivers usually need to take long-distance detours in hitchhiking rides based package deliveries. In this paper, we propose an approach that integrates offline trajectory data mining and online route-and-schedule optimization in the hitchhiking ride scenario to find optimal delivery routes for packages and drivers. Specifically, we propose a two-phase framework for the delivery route planning and scheduling. In the first phase, the historical trajectory data are mined offline to build the package transport network. In the second phase, we model the delivery route planning and package-taxi matching as an integer linear programming problem and solve it with the Gurobi optimizer. After that, taxis are scheduled to deliver packages with optimal delivery paths via a newly designed scheduling strategy. We evaluate our approach with the real-world datasets; the results show that our proposed approach can complete citywide package deliveries with a high success rate and low extra efforts of taxi drivers.

A threshold signature is a special digital signature in which the

Session-based recommendation is a popular research topic that aims to predict users’ next possible interactive item by exploiting anonymous sessions. The existing studies mainly focus on making predictions by considering users’ single interactive behavior. Some recent efforts have been made to exploit multiple interactive behaviors, but they generally ignore the influences of different interactive behaviors and the noise in interactive sequences. To address these problems, we propose a behavior-aware graph neural network for session-based recommendation. First, different interactive sequences are modeled as directed graphs. Thus, the item representations are learned via graph neural networks. Then, a sparse self-attention module is designed to remove the noise in behavior sequences. Finally, the representations of different behavior sequences are aggregated with the gating mechanism to obtain the session representations. Experimental results on two public datasets show that our proposed method outperforms all competitive baselines. The source code is available at the website of GitHub.

Remote photoplethysmography (rPPG) allows remote measurement of the heart rate using low-cost RGB imaging equipment. In this study, we review the development of the field of rPPG since its emergence in 2008. We also classify existing rPPG approaches and derive a framework that provides an overview of modular steps. Based on this framework, practitioners can use our classification to design algorithms for an rPPG approach that suits their specific needs. Researchers can use the reviewed and classified algorithms as a starting point to improve particular features of an rPPG algorithm.
Discourse parsing is an important research area in natural language processing (NLP), which aims to parse the discourse structure of coherent sentences. In this survey, we introduce several different kinds of discourse parsing tasks, mainly including RST-style discourse parsing, PDTB-style discourse parsing, and discourse parsing for multiparty dialogue. For these tasks, we introduce the classical and recent existing methods, especially neural network approaches. After that, we describe the applications of discourse parsing for other NLP tasks, such as machine reading comprehension and sentiment analysis. Finally, we discuss the future trends of the task.

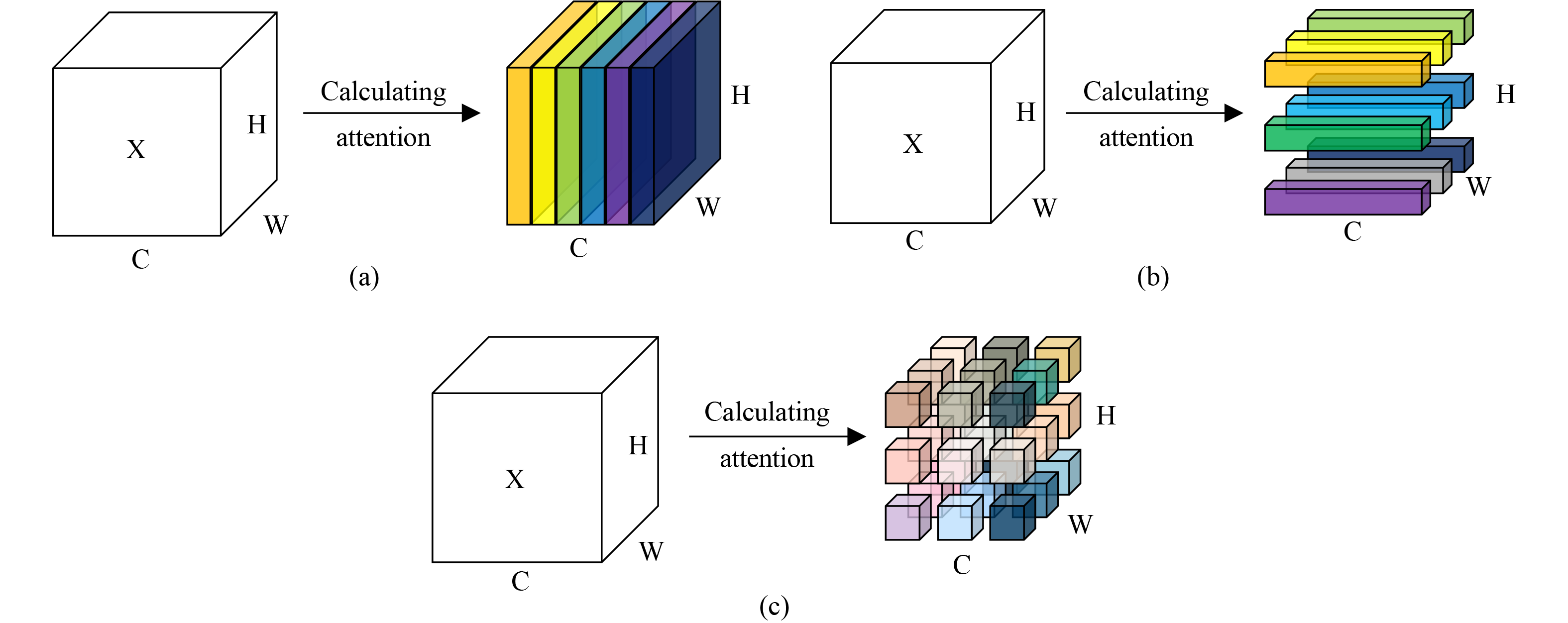
Attention mechanism has become a widely researched method to improve the performance of convolutional neural networks (CNNs). Most of the researches focus on designing channel-wise and spatial-wise attention modules but neglect the importance of unique information on each feature, which is critical for deciding both “what” and “where” to focus. In this paper, a feature-wise attention module is proposed, which can give each feature of the input feature map an attention weight. Specifically, the module is based on the well-known surround suppression in the discipline of neuroscience, and it consists of two sub-modules, Minus-Square-Add (MSA) operation and a group of learnable non-linear mapping functions. The MSA imitates the surround suppression and defines an energy function which can be applied to each feature to measure its importance. The group of non-linear functions refines the energy calculated by the MSA to more reasonable values. By these two sub-modules, feature-wise attention can be well captured. Meanwhile, due to the simple structure and few parameters of the two sub-modules, the proposed module can easily be almost integrated into any CNN. To verify the performance and effectiveness of the proposed module, several experiments were conducted on the Cifar10, Cifar100, Cinic10, and Tiny-ImageNet datasets, respectively. The experimental results demonstrate that the proposed module is flexible and effective for CNNs to improve their performance.
This paper presents a comprehensive survey on the development of Intel SGX (software guard extensions) processors and its applications. With the advent of SGX in 2013 and its subsequent development, the corresponding research works are also increasing rapidly. In order to get a more comprehensive literature review related to SGX, we have made a systematic analysis of the related papers in this area. We first search through five large-scale paper retrieval libraries by keywords (i.e., ACM Digital Library, IEEE/IET Electronic Library, SpringerLink, Web of Science, and Elsevier Science Direct). We read and analyze a total of 128 SGX-related papers. The first round of extensive study is conducted to classify them. The second round of intensive study is carried out to complete a comprehensive analysis of the paper from various aspects. We start with the working environment of SGX and make a conclusive summary of trusted execution environment (TEE).We then focus on the applications of SGX. We also review and study multifarious attack methods to SGX framework and some recent security improvementsmade on SGX. Finally, we summarize the advantages and disadvantages of SGX with some future research opportunities. We hope this review could help the existing and future research works on SGX and its application for both developers and users.
Cognitive diagnosis is the judgment of the student’s cognitive ability, is a wide-spread concern in educational science. The cognitive diagnosis model (CDM) is an essential method to realize cognitive diagnosis measurement. This paper presents new research on the cognitive diagnosis model and introduces four individual aspects of probability-based CDM and deep learning-based CDM. These four aspects are higher-order latent trait, polytomous responses, polytomous attributes, and multilevel latent traits. The paper also sorts on the contained ideas, model structures and respective characteristics, and provides direction for developing cognitive diagnosis in the future.

Heterogeneous information network (HIN) has recently been widely adopted to describe complex graph structure in recommendation systems, proving its effectiveness in modeling complex graph data. Although existing HIN-based recommendation studies have achieved great success by performing message propagation between connected nodes on the defined metapaths, they have the following major limitations. Existing works mainly convert heterogeneous graphs into homogeneous graphs via defining metapaths, which are not expressive enough to capture more complicated dependency relationships involved on the metapath. Besides, the heterogeneous information is more likely to be provided by item attributes while social relations between users are not adequately considered. To tackle these limitations, we propose a novel social recommendation model MPISR, which models MetaPath Interaction for Social Recommendation on heterogeneous information network. Specifically, our model first learns the initial node representation through a pretraining module, and then identifies potential social friends and item relations based on their similarity to construct a unified HIN. We then develop the two-way encoder module with similarity encoder and instance encoder to capture the similarity collaborative signals and relational dependency on different metapaths. Extensive experiments on five real datasets demonstrate the effectiveness of our method.

Community detection methods based on random walks are widely adopted in various network analysis tasks. It could capture structures and attributed information while alleviating the issues of noises. Though random walks on plain networks have been studied before, in real-world networks, nodes are often not pure vertices, but own different characteristics, described by the rich set of data associated with them. These node attributes contain plentiful information that often complements the network, and bring opportunities to the random-walk-based analysis. However, node attributes make the node interactions more complicated and are heterogeneous with respect to topological structures. Accordingly, attributed community detection based on random walk is challenging as it requires joint modelling of graph structures and node attributes.
To bridge this gap, we propose a Community detection with Attributed random walk via Seed replacement (CAS). Our model is able to conquer the limitation of directly utilize the original network topology and ignore the attribute information. In particular, the algorithm consists of four stages to better identify communities. (1) Select initial seed nodes in the network; (2) Capture the better-quality seed replacement path set; (3) Generate the structure-attribute interaction transition matrix and perform the colored random walk; (4) Utilize the parallel conductance to expand the communities. Experiments on synthetic and real-world networks demonstrate the effectiveness of CAS.

Multivariate dynamic networks indicate networks whose topology structure and vertex attributes are evolving along time. They are common in multimedia applications. Anomaly detection is one of the essential tasks in analyzing these networks though it is not well addressed. In this paper, we combine a rare category detection method and visualization techniques to help users to identify and analyze anomalies in multivariate dynamic networks. We conclude features of rare categories and two types of anomalies of rare categories. Then we present a novel rare category detection method, called DIRAD, to detect rare category candidates with anomalies. We develop a prototype system called iNet, which integrates two major visualization components, including a glyph-based rare category identifier, which helps users to identify rare categories among detected substructures, a major view, which assists users to analyze and interpret the anomalies of rare categories in network topology and vertex attributes. Evaluations, including an algorithm performance evaluation, a case study, and a user study, are conducted to test the effectiveness of proposed methods.

Emerging persistent memory technologies, like PCM and 3D XPoint, offer numerous advantages, such as higher density, larger capacity, and better energy efficiency, compared with the DRAM. However, they also have some drawbacks, e.g., slower access speed, limited write endurance, and unbalanced read/write latency. Persistent memory technologies provide both great opportunities and challenges for operating systems. As a result, a large number of solutions have been proposed. With the increasing number and complexity of problems and approaches, we believe this is the right moment to investigate and analyze these works systematically.
To this end, we perform a comprehensive and in-depth study on operating system support for persistent memory within three steps. First, we present an overview of how to build the operating system on persistent memory from three perspectives: system abstraction, crash consistency, and system reliability. Then, we classify the existing research works into three categories: storage stack, memory manager, and OS-bypassing library. For each category, we summarize the major research topics and discuss these topics deeply. Specifically, we present the challenges and opportunities in each topic, describe the contributions and limitations of proposed approaches, and compare these solutions in different dimensions. Finally, we also envision the future operating system based on this study.